係丏扨岅嬫娫専弌幚尡
丂係丏侾丂幚尡忦審
丂杮復偱偼丆QL/W傪梡偄偰丆旕掕忢崅憶壒娐嫬壓偱偺扨岅嬫娫専弌幚尡傪峴偄丆偦偺惈擻傪昡壙偟偨丅扐偟丆崅憶壒壓偱偼柍惡壒巒抂偼専弌崲擄側偨傔丆扨岅壒惡擣幆偺慜張棟偱偁傞扨岅壒惡嬫娫専弌偲偟偰偼丆扨岅偺嵟弶偺桳惡壒嬫娫偺巒抂偐傜嵟屻偺桳惡壒嬫娫偺廔抂傑偱傪扨岅偺嬫娫偲偟偰専弌偡傞偺偑幚梡揑偲峫偊丆埲壓扨岅嬫娫傪偙偺傛偆偵掕媊偡傞丅斾妑偺偨傔丆堦斒揑側峀懷堟怣崋僷儚乕PW丆SIFT朄偵傛傞帺屓憡娭學悢僺乕僋抣AP傪梡偄偨扨岅嬫娫専弌幚尡傕峴偭偨丅
丂丂 娐嫬嶨壒丆榖幰丆掅堟LPC暘愅忦審丆僷儚乕寁嶼忦審丆帺屓憡娭學悢僺乕僋抣寁嶼忦審偼3.2愡偲摨偠偱丆QL/W偺LPC暘愅師悢偼4乣12偱峴偭偨丅QL/W丆PW丆AP偺奺帪宯楍偼3.1ms枅偺奺摿挜検傪嶼弌偟偰媮傔偨丅壒惡丆嶨壒帒椏偼丆旕掕忢憶壒廳忯偑懡偐偭偨100扨岅傪娷傓奺3暘娫傪梡偄偨丅
丂 巒廔抂専弌傾儖僑儕僘儉偵偮偄偰愢柧偡傞丅幚梡揑偵偼憶壒娐嫬壓偱榖幰偺QL/W暘晍傪帠慜偵媮傔傞偙偲偑崲擄偱偁傞偨傔丆嶨壒偺QL/W暘晍偺傒偑婛抦偱偁傞偲偄偆忦審偱丆巒廔抂専弌傪峴偆丅
丂 埲壓丆張棟庤弴傪帵偡丅
丂 乮弨旛乯 傑偢丆偟偒偄抣傪愝掕偟丆桳惡壒嬫娫傪掕媊偡傞丅
丂丂嶨壒嬫娫偵偍偗傞QL/W偺暘晍傛傝丆桳惡壒岓曗丂僼儗乕儉傪専弌偡傞偨傔偺偟偒偄抣V傪愝掕偡傞丅丂偙偺帪丆QL/W亞V偺僼儗乕儉偑桳惡壒岓曗僼儗乕儉丂偱偁傞丅QL/W偺帪宯楍偱丆桳惡壒岓曗僼儗乕儉偑W丂埲忋楢懕偡傞応崌偼丆偙偺嬫娫傪桳惡壒嬫娫F偲丂偟丆W枹枮偺応崌偼偙偺嬫娫傪嶨壒偲傒側偡丅
乮step1乯 QL/W偺帪宯楍偱帪娫幉曽岦偵扵嶕傪奐巒偟丆 嵟弶偺桳惡壒嬫娫F1偺巒揰傪巒抂岓曗TS丆廔揰傪丂廔抂岓曗TE偲偡傞丅
乮step2乯 TE偐傜帪娫幉曽岦偵師偺桳惡壒嬫娫F2傪扵丂嶕偡傞丅TE偐傜F2偺巒揰傑偱偺娫妘傪I偲偡傞丅丂偙偺帪丆壓婰偺扨岅岓曗嬫娫宲懕忦審傪枮偨偣偽丆丂F1偐傜F2傑偱扨岅嬫娫偑宲懕偟偰偄傞偲敾抐偟偰丆丂F2偺廔揰傪TE偲偟偰峏怴偡傞丅
丂扨岅岓曗嬫娫宲懕忦審丗I亝200ms(64僼儗乕儉)偱偁傞丅
丂峏偵丆屻懕偺桳惡壒嬫娫傪摨條偵扵嶕丒張棟偡傞丅 乮step3乯 忋婰偺宲懕忦審傪枮偨偡Fi偑懚嵼偟側偐偭 偨帪揰偱丆1偮偺扨岅嬫娫偺扵嶕傪廔椆偡傞丅偦偟丂偰丆F1偐傜Fi-1傑偱偺奺桳惡壒嬫娫偺憤榓偑100ms丂埲忋偺応崌偵偙偺嬫娫傪扨岅嬫娫G1偲寛掕偡傞丅丂偙偺帪偺TS丆TE偑G1偺奺乆巒抂丒廔抂岓曗偱偁傞丅丂堦曽丆憤榓偑100ms枹枮偺応崌偼嶨壒偲偟偰彍嫀偡傞丅
丂偙偙偱丆Fi偼師偺扨岅嬫娫偺嵟弶偺桳惡壒嬫娫F1 偱偁傞偲偟偰乮step1乯偵栠傞丅
丂偟偒偄抣V偍傛傃W偼丆埲壓偺忦審偱専摙偟偨丅 偟偒偄抣丗V=(兪俶亄2冃俶) dB, W=21.9ms (7僼儗乕儉)兪俶丆冃俶偼丆妛廗帒椏偵偍偗傞嶨壒偺QL/W偺暯嬒丆昗弨曃嵎偱偁傞丅
丂AP 偵傛傞巒廔抂専弌曽朄偼QL/W偲摨條偱偁傞丅扐偟丆忋弎偺偟偒偄抣忦審偱偼扙棊岆傝偑懡偐偭偨偨傔丆偙偺忦審埲奜偵W=40.6ms傑偨偼21.9ms丆V亖0.25乣
0.35乮0.025枅乯偺斖埻偱嵟傕専弌惈擻偺崅偄忦審偱偺専弌幚尡傕峴偭偨丅
丂PW偵傛傞巒廔抂専弌曽朄偼丆廬棃庤朄傪嶲峫偵偟偰埲壓偺傛偆偵峴偭偨丅傑偢嬫娫専弌偺懳徾偲側傞椞堟偵偍偄偰嵟戝僷儚乕偑PMAX埲忋偲側傞揰傪媮傔丆偙偺揰傪婲揰偵PW偑掕忢嶨壒僷儚乕儗儀儖偵掅壓偡傞揰傪専弌偡傞丅PW偑掕忢嶨壒僷儚乕儗儀儖傪挻偊傞僼儗乕儉偑丆40.6ms埲忋楢懕偡傞応崌偵偙偺嬫娫傪桳惡壒嬫娫偲偟偰丆帪娫幉曽岦偵廔抂岓曗丆媡曽岦偵巒抂岓曗傪扵嶕偡傞丅扨岅嬫娫偺宲懕傪敾抐偡傞婎弨偼QL/W偲摨條偱丆桳惡壒嬫娫偺憤榓偑100ms埲忋偺巒廔抂岓曗傪専弌偡傞丅PMAX偼丆巊梡偟偨100扨岅偺拞偱丆嵟戝僷儚乕偑嵟傕彫偝偄扨岅偺嵟戝僷儚乕抣偵愝掕偟偨丅
丂係丏俀丂幚尡寢壥
丂 惓偟偄巒廔抂偼丆帇嶡偵傛傝媮傔偨丅栚帇偱妋擣偟偨埵抲傪婎弨偵巒抂偱亇25ms乮8僼儗乕儉乯丆廔抂偱亇50ms乮16僼儗乕儉乯埲撪偵専弌偝傟偨応崌傪惓夝偲偟偨丅巒抂丆廔抂偲傕偵惓夝偺応崌傪惓夝嬫娫偲偟丆嬫娫専弌棪傪埲壓偺傛偆偵嶼弌偟偨丅
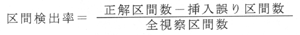
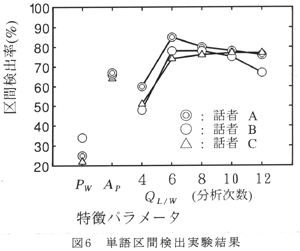 丂恾6偼丆3柤偺榖幰偺専弌棪傪帵偟偰偄傞丅AP偼嵟傕専弌棪偺崅偐偭偨忦審乮V亖0.3丆W=40.6ms乯偱偺寢壥傪帵偟偰偄傞丅PW偱偼壒惡巒廔抂嬤朤偵旕掕忢嶨壒偑懚嵼偡傞応崌偼丆傎偲傫偳偑岆専弌偲側傞丅QL/W偱偼暘愅師悢6師埲忋偱扨岅嬫娫専弌惈擻偑岦忋偡傞偙偲偑傢偐傞丅3柤偺QL/W偱偺専弌棪偺暯嬒偼丆暘愅師悢6師偱偼79.0亾丆8師偱偼78.0亾偱偁傞丅偙傟偵懳偟偰丆3柤偺AP偱偺専弌棪偺暯嬒偼丆65.7亾偱偁傞丅偄偢傟偺榖幰傕QL/W偑AP傪忋夞偭偰偄傞丅
丂恾6偼丆3柤偺榖幰偺専弌棪傪帵偟偰偄傞丅AP偼嵟傕専弌棪偺崅偐偭偨忦審乮V亖0.3丆W=40.6ms乯偱偺寢壥傪帵偟偰偄傞丅PW偱偼壒惡巒廔抂嬤朤偵旕掕忢嶨壒偑懚嵼偡傞応崌偼丆傎偲傫偳偑岆専弌偲側傞丅QL/W偱偼暘愅師悢6師埲忋偱扨岅嬫娫専弌惈擻偑岦忋偡傞偙偲偑傢偐傞丅3柤偺QL/W偱偺専弌棪偺暯嬒偼丆暘愅師悢6師偱偼79.0亾丆8師偱偼78.0亾偱偁傞丅偙傟偵懳偟偰丆3柤偺AP偱偺専弌棪偺暯嬒偼丆65.7亾偱偁傞丅偄偢傟偺榖幰傕QL/W偑AP傪忋夞偭偰偄傞丅
丂傑偨丆斾妑揑僺僢僠廃攇悢偺崅偐偭偨榖幰A偼丆榖幰B丆C傛傝傕丆掅師悢乮4師丆6師乯偱岠壥偑崅偐偭偨丅偙偺偙偲偼丆杮僺僢僠懳墳宆掅堟LPC儌僨儖偑惓偟偔婡擻偟偰偍傝丆憐掕偝傟傞嬌悢偐傜摼傜傟傞師悢埲忋偱偁傟偽丆桳惡壒偵揔崌偟嶨壒拞偐傜偺扨岅嬫娫専弌偑壜擻偱偁傞偙偲傪帵偟偰偄傞丅